Deep Residual Network实验复现

1. Deep Residual Network
在2015年的ImageNet比赛中,MSRA的He Kaiming用deep residual network取得了惊人的成果,不仅在多个task上排名榜首,而且远超第二名好多好多。
这极大的引起了我对Deep Residual Network的好奇心,想要玩一玩Deep Residual Network。
2. 论文解析
这个暂时不做了,google一搜会有大把的blog
3. 实验结果复现进展
由于ImageNet的数据集很大,尝试需要大量时间,我只是在cifar10这个数据集上进行了尝试。结果虽然没有论文中那么高,但是我通过实验确实发现deep residual network有奇效,
我给MXNet提交了一个example,并且已经merge到官方的MXNet中,也是我人生中第一个github的pull request。我的github链接或者官方链接,怎么使用都在脚本里面说明了。
3.1 我尝试的结果
- 20层的resnet, accuracy=0.905+, 论文中是0.9125
- 32层的resnet, accuracy=0.908+, 论文中是0.9249
- 56层的resnet, accuracy=0.915+, 论文中是0.9303
3.2 结论
The Deeper, The Better
越深当然越好啊!
- 比论文差,因为网络设置上与论文中不同,下节3.3会说明
- 同时,我也尝试了上面各种resnet所对应的plain network(就是不加shortcut的常规网络),发现层数越多,accuracy越低,这个结果也是和论文相符的
3.3 为什么的结果与论文中不一致
- 论文中cifar10的最初输入是先对每一张32x32的图周围padding 4个像素,然后再随机crop出一个32x32的图,而我是用了MXNet官方提供的cifar10的数据压缩文件,并没有先做padding而是从32x32的图中随机crop出一个28x28的图,所以我的网络结构中feature map的size是28x28, 14x14, 7x7这三种,论文中对应的是32x32, 16x16, 8x8
- 论文中在cifar10上连接shortcut的时候处理dimension increase用的是option A(就是padding过后的identity mapping),目前MXNet没有这个功能,所以我用的是projection short(也就是option B)
- 不同的框架实现上稍有不同,对于同样的数据集,采用一样的training方法和hyper parameter设置,结果也有些许差异。我和我的同学,用caffe、MXNet、cuda-convnet等不同deep learning的框架做其他任务的时候就发现了这个现象。
4. 值得讨论的地方
4.1 shortcut连接细节
论文中虽然说了shortcut怎么连接,但是有一个地方非常模糊,就是在哪里加batch normalization
比如下图是一个Residual Network的一个block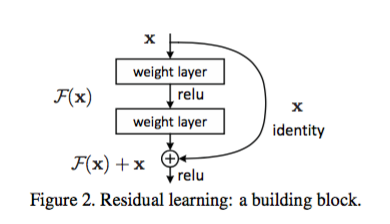
论文中说:
We adopt batch normalization (BN) [16] right after each convolution and
before activation, following [16].
[16]: S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
- 这里第一个weight layer很明确,先做convolution,接着batch normalization,然后relu,送到下一层
- 第二个weight layer就很难说了,这里有多重情况
- 先convolution,接着BN,然后和identity shortcut(option A)相加,经过relu
- 先convolution,然后和identity shortcut(option A)相加,接着BN,经过relu
- 同样采用option B的时候也有多种情况,要先对shortcut做一个convolution,那么这个shortcut要先做BN吗,还是要相加之后再做BN
4.2 Activation是否一定是relu
论文中说:
We use a weight decay of 0.0001 and momentum of 0.9, and adopt the weight initialization in [13] and BN [16] but with no dropout.
[13]: K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[13]也是He Kaiming的paper,在deep residual network中他们的weight初始化是参考[13]的,并且在[13]中他们提出了一个PReLU,而本论文中的图都是ReLU,这里我就有两个疑问了:
- 在deep residual network中作者实际采用的是不是不是ReLU,而是PReLU,图中的ReLU只是一个示例
- 作者其实试验过PReLU,相较而言ReLU在residual network上表现更好,所以还是采用了ReLU
这些都需要我们用实验去验证