Implement L2 Normalization Layer in Caffe

转载请注明!!!
Sometimes we want to implement new layers in Caffe for specific model. While for me, I need to Implement a L2 Normalization Layer. The benefit of applying L2 Normalization to the data is obvious. The author of Caffe has already wrote methods to add new layers in Caffe in the Wiki. This is the Link
有的时候我们需要在Caffe中添加新的Layer,现在在做的项目中,需要有一个L2 Normalization Layer,Caffe中居然没有,所以要自己添加。添加方法作者已经在Caffe的wiki上写出来了,Link How To Implement New Layers in Caffe
所以最重要的是如何实现forward_cpu(forward_gpu), backward_cpu(backward_gpu).
1. L2 Normalization Forward Pass(向前传导)
1.1 Formula Deduction(公式推导)

1.2 Implementation(实现)
1 | template <typename Dtype> |
2. L2 Normalization Backward Propagation
2.1 Formula Deduction(公式推导)
First is the gradient regardless of upper layer:

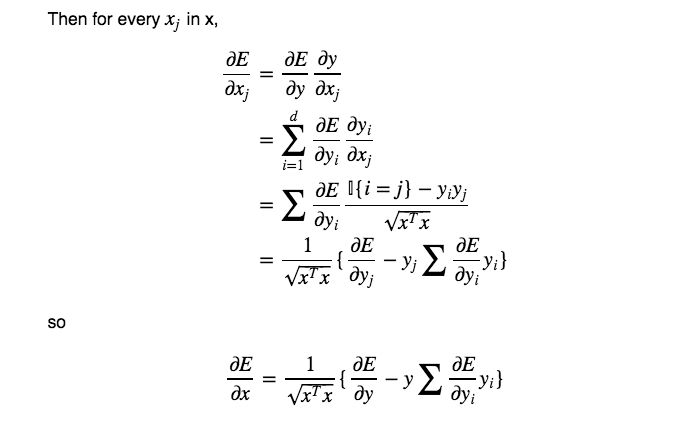
2.2 Implementation(实现)
1 | template <typename Dtype> |
3. Full Codes
I just give the necessary GPU version codes.
For full Implementation of CPU, GPU and other necessary codes, please go to my Github repository for more imformation. link
我给出的只是部分的GPU代码,如果想要看完整的整个layer的实现,请看link
4. Improvements
the codes above is just for easy understanding how to implement L2 normalization layer.
Thought the GPU version is fast , it still is not the fastest one. You can use caffe_gpu_gemv(calling cublasDgemv or cublasSgemv) and other functions to calculate all the gradients at once as possible as you can, not like the one above calculating sample by sample.
上面的代码只是一个比较简单的L2 Normalization这一层,而且为了能够易于理解,并没有写最快的版本,事实上可以用caffe_gpu_gemv(会调用底层的cublasDgemv或者cublasSgemv),来一次性计算所有的梯度(gradient),而不是像上面那样只是一个一个的算梯度.。