A Survey of 3D Facial Animation

Binbin Xu
Abstract:
3D Facial Animation is a hot area in Computer Vision. There are two main tasks of facial animation, which are techniques to generate animation data and methods to retarget such data to a character while retains the facial expressions as detailed as possible. The emergence of depth cameras, such as Microsoft Kinect has spawned new interest in real-time 3D facial capturing and some related field. In this survey I will focus on the recent technology development in 3D facial Animation using such RGB-D cameras and ordinary cameras just with RGB data.
Key words: RGB-D, Blendshape, Face Alignment, 3D Facial Animation, PCA-model
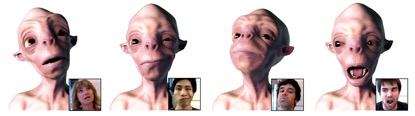
3D Facial Animation is a hot area in Computer Vision. There are two main tasks of facial animation, which are techniques to generate animation data and methods to retarget such data to a character while retains the facial expressions as detailed as possible. Facial Animation is crucial to Film and game production, for example there are a lot of Hollywood movies that use such technologies.
1.Facial Performance Capture
In real application especially in the field of film and game production they use special instrument to capture facial performance. Marker-based systems(for example [1][2]) are widely used. Some uses camera arrays or multi-view systems(for example [3]) to achieve the goal, while [4][5] adopt structured light scanners. The above techniques, however, require specialized hardware and need sophisticated setups and careful calibration, further the expensive equipment make it unsuitable for consumer level applications.
The emergence of depth cameras, such as Microsoft Kinect, Asus Xtion and Intel Real-sense (most of these cameras based on the structured light tech) and so on, has spawned new interest in real-time 3D facial capturing and some related field.
Weise et al[6] start the area just using commercial cameras to do 3D facial Animation in 2011, they use Kinect with RGB-D data. While Cao et al[7][8] just use ordinary web-cameras to do 3D facial Animation based on Weise and other researchers work. In this survey I will focus on the recent technology development in 3D facial Animation using such RGB-D cameras and cameras just with RGB data.
2. Blendshape Model

Blendshape Model is based on the FACS(Facial Action Coding System)[9]. As the above picture presents, An Blendshape Model $(B=[B_0,B_1,…,B_n], n=46)$ contains the user’s neutral face mesh plus 46 blendshapes (number of blendshapes can be defined according to specific tasks) based on the user’s different expressions. With these blendshapes, a user’s facial expression can represented as $B = B_0+ \sum {a_i}*{B_i}$, where $(a=[a_1,a_2,…,a_n], n=46)$ is a vector of expression coefficients.
There are some available dataset. FaceWarehouse[10] is a database of 3D facial expressions for visual computing applications. Using a Kinect RGBD camera, they captured 150 individuals aged 7-80 from various ethnic backgrounds. EURECOM Kinect Face Dataset has images of different facial expressions in different lighting and occlusion conditions to serve various research purposes.
3. Face Alignment

On a face mesh is a set of landmark vertices, which correspond to certain facial features such as eye corners, nose tip and other important points as the above picture illustrates. These feature landmarks are essential in mapping the expression from the users to digital avatars especially useful when using cameras only with RGB data.
Face Alignment is very popular research field. In recent researches, using Deep Learning to predict the landmarks [11] become a trend (Facebook AI Research, face++ etc. uses this kind of technology). But it cannot satisfy the real-time requirement in this 3D facial Animation field because Deep Convolution Neural Networks has very large parameters and often need high performance GPU devices.
On the other hand, Active Appearance Models [12] solves the face alignment problem by jointly modeling holistic appearance a shape. Constrained Local Model [13][14] learns a set of local detectors or regressors and constrains them using various models. Most papers adopt multiple stages regression method called Cascade Pose Regression (CPR), with an estimated Pose at the previous stage as the next stage’s input, then output the refined pose estimation at current stage. The current state-of-the-art is [15] which at each stage first using random forest learns a set of local binary features and then using a global linear regression to get a global generalization, the estimated parameters can refined stage by stage. This algorithm can achieve 3000+ fps on a normal computer and 300+ fps on a mobile phone when doing face alignment.
4. PCA Model
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. And PCA can be used to do dimension reduction. In 2D face research, the principal components are called eigenfaces, any face can be represented as a linear combination of those eigenfaces. And it holds true for 3D face, the PCA model comes from a morphable model proposed in [16]. Suppose there a set of 3D faces, and $m$ is the mean face and $P=[p_1,p_2,…,p_l]$ is the first $l$ PCA eigenvectors. With such an orthonormal basis, a user’s neutral expression can be approximated as $B_0=m+Py$ with $y$ as linear coefficients.
5. ICP Algorithm
Since the raw depth data from Kinect has big noise and is incomplete. Iterative Closest Point (ICP) is an algorithm employed to minimize the difference between two clouds of points. ICP is often used to reconstruct 2D or 3D surfaces from different scans, to localize robots and achieve optimal path planning, to co-register bone models, etc. There are many variant ICP methods.
6. Workflows of Recent State-of-the-art 3D facial Animation Systems
No matter what the specific methods are used in recent facial Animation systems, the main workflow are similar. And one key tech is they all adopt Blendshape Model.
Let’s take Weise et al[6] for example, see the work pipeline below.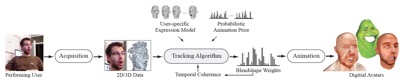
First they aggregate multiple input depth map frames using a rigid alignment based on the fast iterative closest point method (ICP) to obtain a merged 3D point cloud with better coverage of the face. The blendshape weights that drive the digital avatar are estimated to obtain non-rigid facial detailed by solving a MAP problem in which a probabilistic animation prior learned from existing blendshape is used. Temporal coherence is exploited by considering a window of consecutive frames.
Paper [17] is based on [6], the adopt the PCA model, using the PCA model to obtain rigid neutral expression and using non-rigid ICP algorithm[18] to refine the details of non-rigid part. Then they use this neutral blenshape to obtain 23 other blendshapes using the deformation transfer algorithms in [19].
$B_i={T_i}*{B_0},\;T_i\;is\;the\;transfer\;matrix.$
When in real-time tracking, the adaptive PCA model will refine the blendshapes by using a Laplacian deformation algorithm along with 2D features and depth data.
Paper [20] is similar to [17], but they use corrective deformation fields to obtain the user-specific details. Per-vertex displacements are modeled using a spectral representation defined by the k last eigenvectors $E=[e_1,e_2,…,e_k]$ of the graph Laplacian matrix L computed on the 3D face mesh. A smooth deformation field can then be defined as a linear combination , where z is the spectral coefficients. So
$B_0=m+Py+Ez_0,\;\; B_i=T_i*B_0+Ez_i$
By adding rotation matrix $R$ and translation vector $t$ at each frame, the PCA model is refined by aggregation of history of observed expression data. The blendshapes weights are estimated by minimizing an energy function. This system requires no user-specific training or calibration, or any other form of manual assistance.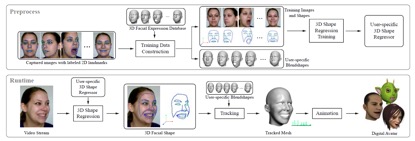
Instead of using RGB-D cameras, Paper [8] just uses an ordinary camera only with RGB data. In the above picture, at first the user has to take some pictures of different poses. Then landmarks of each image will be labeled out by a Face Alignment program and can be correct manually if necessary. User-specific Blendshapes are then generated by mapping the 2D landmarks to 3D landmarks using a bilinear face model (details should be refer to [8]). All of the input images and their 3D facial shapes are then used to train a user specific 3D shape regressor. With this regressor the 3D facial shape for each video frame can be computed in real time. The regressor adopts two level boosted regression approach to refine the estimated parameters for each in coming frame. And the coefficients of the blendshapes are solved by minimizing an energy function which is added with an animation prior (similar to [6]) to enhance temporal coherence. And the model needs camera calibration.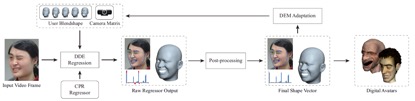
Paper [9] is based on [8], it is a calibration free approach and the user does not have to take some pictures. The workflow is depicted as above. The input video frame I is first sent into a CPR regressor, formulated as a function mapping a guessed shape vector $P(in)$ to a regressed shape $P(out)$, the regressor output is then post-processed to improve the temporal coherence and clamp expression coefficients. The post-processed output is optionally sent to an iterative optimization procedure to update the camera matrix and other parameters. The optimized parameters are sent back to the CPR regressor in a feedback loop. The final shape vector is transferred to drive the digital avatars.
7. My thoughts and work
In the above 5 systems, paper [6] and [8] need user-specific training or calibration, while the other 3 are calibration free. And [6][17][20] use RGB-D cameras, while [8] [9] just use ordinary cameras only with RGB data. Because [6] starts this area, so it has many limitations, animation prior need large training data, the resolution of the acquisition system limits the amount of geometric and motion details and need manual markup of lip and eye features to register the generic template. The expressions retarget to the digital avatars are obviously not good enough. [17] and [20] both use the PCA model and with some correctives, the expression details are more accurate than [6], while they still fail to capture some details beacuse the blendshapes are generated by transforming the neutral blendshape. Though [8] just uses ordinary cameras, it captures images of different poses of the user and builds blendshapes by mapping the corresponding 2D images to 3D face meshes, so the system can retain more details. The main drawback is it needs user-specific training and camera calibration. And intuitively speaking, mapping 2D information to 3D is inferior than directly using the RGB-D data. [9] is a big improvement to [8], which does not need any calibration. It only runs at 24fps, which remains a lot of things to do. All the 5 models above may fail if the face is partially occluded.
To improve the tracking accuracy especially when labeling landmarks, the current state-of-the-art face alignment [15] can be used, it has good accuracy and fast speed. And [21] proposes a combined hardware and software solution for markerless reconstruction of non-rigidly deforming physical objects with arbitrary shape in real-time. They adopt RGB-D data and a novel GPU based pipeline. I think using this GPU based approach can significantly improve the expression details reconstruction in the 3D facial Animation and speed up the computation. [22] proposes a method called PCPR handles the occlusion stuff. RCPR outperforms previous landmark estimation work on four different, varied face datasets. RCPR is more robust to bad initializations, large shape deformations and occlusion. Off course, other techs that will drive better performance can also be used in 3D facial Animation, let’s wait for new methods to come.
My current work is to use Intel RealSense (a device similar to Microsoft Kinect that has RGB-D data, but with less noise, and better accuracy for depth) to do face verification. For example, there are methods by scanning user’s face to unlock the door. But those approaches just use 2D information, if the user’s face is partially occluded (especially for women who have long hairs that occludes their faces), the verification process may fail, and it is hard to distinguish the twins because their faces are almost identical. We believe using 3D information will improve the performance because use the depth data we can obtain the true skeleton of the user’s face.
8. Available Consumer-level 3D Facial Animation Products
- Face Plus:
Markerless Facial Capture and Facial Animation, in Real Time. With Face Plus, all you need to do is sit down in front of a webcam, act out the expressions you want to apply to your 3D character, and watch it happen in real time within your 3D game engine. - Faceshift:
Faceshift first scans a set of expressions to train your personalized avatar for tracking. And then capture a performance with realtime feedback, and optionally improve the accuracy in a postprocessing stage. Last animate virtual avatars in faceshift and export the animation to your favorite 3D animation software, or connect to your existing animation pipeline. - CubicMotion:
Similar to the above two.
9. References
[1]: HUANG, H., CHAI, J., TONG, X., AND WU, H. 2011. Leveraging motion capture and 3d scanning for high-fidelity facial performance acquisition. ACM Trans. Graph. 30, 74:1–74:10.
[2]: DENG, Z., CHIANG, P.-Y., FOX, P., AND NEUMANN, U. 2006. Animating blendshape faces by cross-mapping motion capture data. In I3D, 43–48.
[3]: BRADLEY, D., HEIDRICH, W., POPA, T., AND SHEFFER, A. 2010. High resolution passive facial performance capture. ACM Trans. Graph. 29, 41:1–41:10.
[4]: WEISE, T., LI, H., GOOL, L. V., AND PAULY, M. 2009. Face/off: Live facial puppetry. In SCA, 7–16.
[5]: ZHANG, L., SNAVELY, N., CURLESS, B., AND SEITZ, S. M. 2004. Spacetime faces: high resolution capture for modeling and animation. ACM Trans. Graph. 23, 548–558.
[6]: WEISE, T., BOUAZIZ, S., LI, H., AND PAULY, M. 2011. Realtime performance-based facial animation. ACM Trans. Graph. 30, 77:1–77:10.
[7]: CAO, C., WENG, Y., LIN, S., ZHOU, K. 2013. 3D shape regression for real-time facial animation. ACM Trans. Graph. 32,4(July), 41:1-41:10.
[8]: CAO, C., HOU, Q., ZHOU, K. 2014. Displaced dynamic expression for real-time facial tracking and Animation. ACM Trans. Graph.
[9]: EKMAN, P., AND FRIESEN, W. 1978. Facial Action Coding System: A Technique for the Measurement of Facial Movement. Consulting Psychologists Press.
[10]: CAO, C., WENG, Y., ZHOU, S., TONG, Y., AND ZHOU, K. 2013. Facewarehouse: a 3D facial expression database for visual computing. IEEE TVCG.
[11]: TAIGMAN, Y., YANG, M., RANZATO, M., WOLF, L. 2014. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on.
[12]: COOTES, T., EDWARDS, G., TAYLOR, J. 2011. Active appearance models. Pattern Analysis and Machine Intelligence, IEEE Transactions on
[13]: ZHU, X., and RAMANAN, D. 2012. Face detection, pose estimation, and landmark localization in the wild. In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on.
IEEE, 2012. 2, 5
[14]: BALTRUˇSAITIS, T., ROBINSON, P., AND MORENCY, L.-P. 2012. 3d constrained local model for rigid and non-rigid facial tracking. In CVPR, 2610–2617.
[15]: REN, S., CAO, X., WEI, Y., SUN, J. 2014. Face alignment at 3000fps via regression local binary features. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on.
[16]: BLANZ, V., AND VETTER, T. 1999. A morphable model for the synthesis of 3d faces. In Proc. SIGGRAPH, 187–194.
[17]: LI, H., YU, J., YE, Y., AND BREGLER, C. 2013. Realtime facial animation with on-the-fly correctives. ACM Trans. Graph. 32, 4 (July), 42:1–42:10.
[18]: LI, H., ADAMS, B., GUIBAS, L. J., AND PAULY, M. 2009. Robust single-view geometry and motion reconstruction. ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2009) 28, 5.
[19]: SUMNER, R. W., AND POPOVI´C , J. 2004. Deformation transfer for triangle meshes. ACM Trans. Graph. 23, 3 (Aug.), 399–405.
[20]: BOUAZIZ, S., WANG, Y., AND PAULY, M. 2013. Online modeling for realtime facial animation. ACM Trans. Graph. 32, 4 (July), 40:1–40:10.
[21]: ZOLLHOFER, M., NIEBNER, M. et al. 2014. Real-time Non-rgid reconstruction using an RGB-D camera. ACM Trans. Graph.
[22]: BURGOS-ARTIZZU, X., PERONA, P., and DOLLAR, P. 2013. Robust face landmark estimation under occlusion. ICCV